Table of Contents
Introduction Linear Regression Logistic Regression Decision Trees Random Forests K-Nearest Neighbors Support Vector Machines Naive Bayes ConclusionIntroduction
Data science is an interdisciplinary field that involves using statistical and computational methods to extract insights and knowledge from data. To do this effectively, data scientists must be proficient in a variety of algorithms and techniques that are commonly used in the field. Here are some of the most important algorithms that every data scientist should know.

Linear Regression
Linear regression is a statistical technique used to model the relationship between two variables by fitting a linear equation to the observed data. It is a simple but powerful algorithm that can be used to predict continuous values, such as stock prices or housing prices, based on one or more predictor variables.
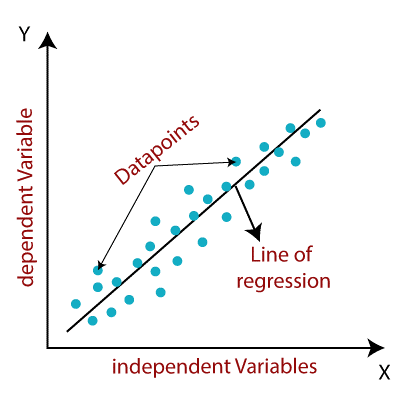
Examples
Credit Scoring
Linear regression can be used to score the creditworthiness of an individual or a business based on their credit history, income, and other relevant factors.
Stock Price Prediction
Linear regression can be used to predict the future prices of stocks based on their past prices and other relevant factors such as market trends, company performance, and economic indicators.
Logistic Regression
Logistic regression is a classification algorithm used to predict the probability of an event occurring, based on one or more predictor variables. It is commonly used in binary classification problems, where the goal is to predict whether an event will occur or not. Logistic regression is widely used in fields such as healthcare, finance, and marketing.

Examples
Customer Segmentation
Logistic regression can be used to segment customers based on their demographics, purchase behavior, and other relevant factors. This can help businesses to target their marketing campaigns more effectively.
Fraud Detection
Logistic regression can be used to detect fraudulent transactions based on patterns in the transaction data, such as unusual amounts, locations, or times of day.
Spam Filtering
Logistic regression can be used to filter out spam emails based on the content of the email and the sender’s information.
Decision Trees
A decision tree is a hierarchical model that represents decisions and their consequences as a tree. It is a widely used algorithm in machine learning, data mining, and statistics. Decision trees are commonly used for classification and regression analysis. They are easy to interpret and can handle both categorical and numerical data.
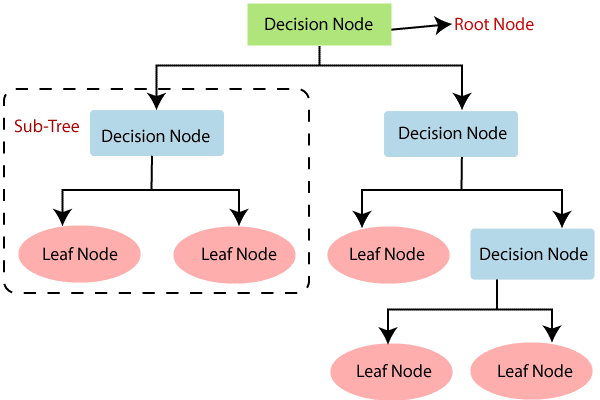
Examples
Product Recommendation
Decision trees can be used to recommend products to customers based on their past purchase history and other relevant factors.
Medical Diagnosis
Decision trees can be used to diagnose diseases based on patient symptoms, medical history, and other relevant factors.
Random Forests
Random forests are a type of ensemble learning algorithm that combines multiple decision trees to make predictions. They are used for both classification and regression problems and are known for their high accuracy and robustness. Random forests are widely used in various fields, including finance, healthcare, and marketing.
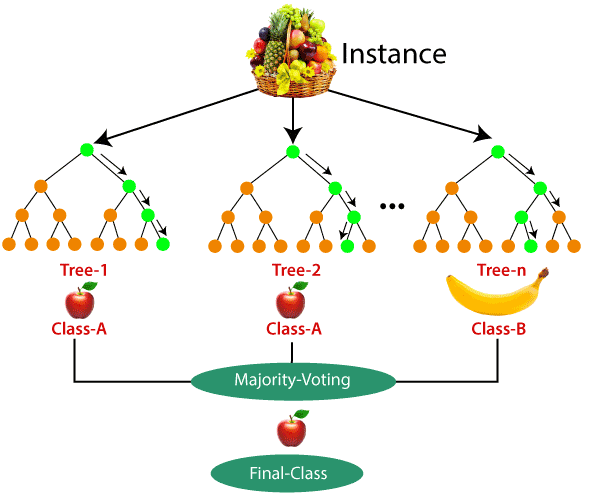
Examples
Image classification
Random forest can be used to classify images by analyzing features such as color, shape, and texture.
Credit risk analysis
Random forest can be used to predict credit risk by analyzing data such as credit history, payment behavior, and other financial indicators.
K-Nearest Neighbors
K-Nearest Neighbors (KNN) is a simple but powerful algorithm used for classification and regression analysis. It is a non-parametric algorithm that does not make any assumptions about the underlying data distribution. KNN works by finding the k nearest neighbors to a new data point and using their labels or values to make a prediction.
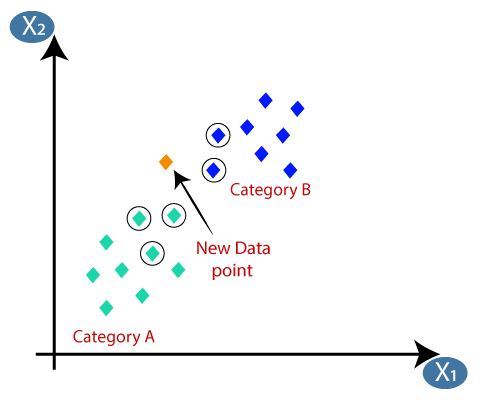
Examples
Recommender systems
KNN can be used to recommend products or services to users based on the behavior of similar users. For example, an e-commerce site might recommend products to a user based on the purchases of similar users.
Anomaly detection
KNN can be used to detect anomalies in data by comparing each data point to its K-nearest neighbors. For example, a cybersecurity system might use KNN to detect unusual network activity by comparing each network event to its K-nearest neighbors.
Support Vector Machines
Support Vector Machines (SVMs) are a type of supervised learning algorithm used for classification and regression analysis. SVMs are particularly useful in cases where the data is high-dimensional and not easily separable. They work by finding the hyperplane that maximizes the margin between the two classes.
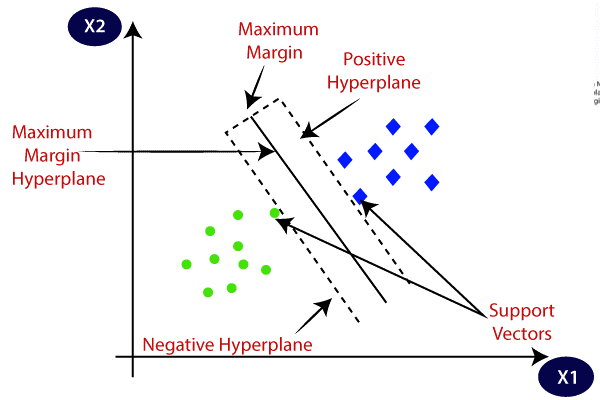
Examples
Text classification
SVM can be used to classify text into categories such as spam/not spam or positive/negative sentiment.
Face detection
SVM can be used to detect faces in images by analyzing features such as color, shape, and texture.
Naive Bayes
Naive Bayes is a probabilistic algorithm used for classification and regression analysis. It is based on Bayes’ theorem, which states that the probability of a hypothesis (i.e., a prediction) is proportional to the prior probability of the hypothesis and the likelihood of the data given the hypothesis. Naive Bayes is particularly useful in cases where the data is high-dimensional and not easily separable.
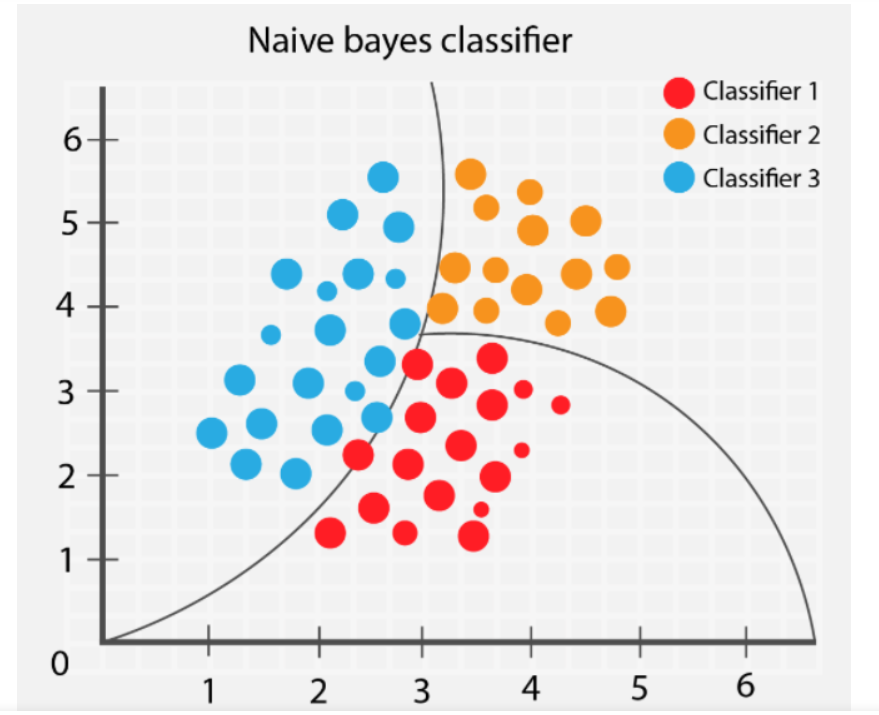
Examples
Text classification
Naive Bayes can be used to classify text into categories such as spam/not spam or positive/negative sentiment.
Customer segmentation
Naive Bayes can be used to segment customers based on their behavior or characteristics. For example, a marketing campaign might target a group of customers who are similar to each other in terms of their purchase history.
Medical diagnosis
Naive Bayes can be used to diagnose medical conditions by analyzing patient data such as symptoms, lab results, and other medical indicators.

Conclusion
These are just some of the many algorithms that data scientists should be familiar with. Understanding the strengths and weaknesses of different algorithms is essential for choosing the right approach for a given problem. Additionally, data scientists must also be proficient in programming languages and tools such as Python, R, SQL, and machine learning frameworks such as TensorFlow and PyTorch. With the right algorithms and skills, data scientists can extract valuable insights and knowledge from data that can be used to drive business decisions and improve outcomes in various fields.